
Support Vector Machine is a famous, versatile, and robust classification algorithm in machine learning. It is widely applied in various fields from protein folding to handwriting recognition. In this post, I will attempt to explain and then implement SVM using real-world data.
In this blog post, I will be mainly speaking to SVM employed in binary classification, which means the output variables, or the class, are binary. For instance, this can mean whether the handwriting came from a male or a female, whether an image contains a dog or a cat. etc.
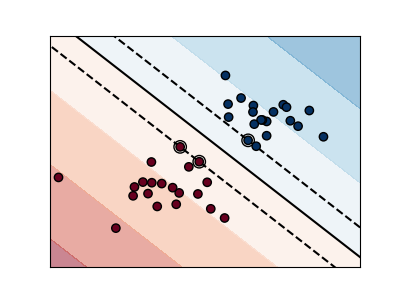
Before we step into SVM, I want to first talk about dimensions. Say you have something like this
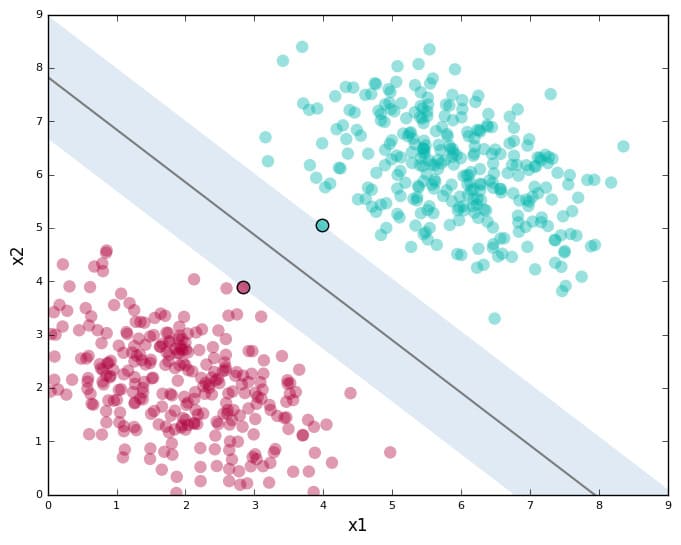
The graph is in 2D, meaning each data point is represented by $(x, y)$. In this case, the SVM, which is simply a straight line that separates the two classes, is in one dimension. However, in cases where each data point consists of more than two features, which may be represented in a 3D coordinate plane in the form of $(x, y, z)$, it might look something like this below
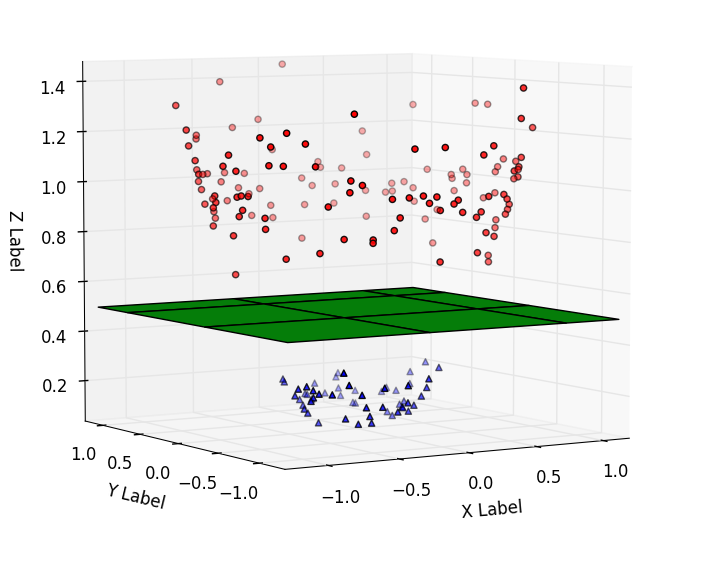
Here, the line separating the two classes became a plane (the math jargon for these separators are called hyperplanes), which is 2 dimensional. You get the pattern. The hyperplane is always $n-1$ dimensional, where $n$ is the number of features. Furthermore, in machine learning, or my implementations later in this post, data can have as many dimensions as you want, but we humans simply can't visualize them. That's why most of the visualizations of SVM you see on the internet are either two or three dimensional.
The hyperplane that I just spoke about is the key in SVM - but not any hyperplane that separates the dataset into two classes - one that maximizes the margin between the minimum distanced support vectors. In other words, you want to separate the closest data points (these are called support vectors) from the hyperplane as much as possible. The math looks something like this below, which is about optimizing a convex function and solving partial derivatives. If you wish to read further about the math, I suggest you read a book published by Stanford University on this matter.

It is amazing how math notations resemble programming syntax. Here, the $max$ operator simply returns the maximum value outputted by the function $g$.
After you build the model, the way you predict whether a new data point would fall within either of the classes is by taking the dot product of the vector form of the new data point and a vector that points perpendicularly to that hyperplane from the origin. Let $\vec{v}$ be the new data point and let $\vec{w}$ be the vector that points perpendicularly to the hyperplane.

You then add another term $b$ which associates with the bias of the model and see whether the final value is bigger than 1 or smaller than -1, which respectfully represent the binary classifications of the output variable
I found a dataset from Kaggle.com about wine quality classification. The data looks something like this, with 11 labels and a quality column that rates the wines from 1 to 10.

I wanted to simply demonstrate a binary classification so I replaced the values higher or equal than 5 in the quality column with 1 and values lower than 5 with 0. Note that the dataframe.where() method depends on the boolean value of the first parameter. The method doesn't replace the value with 1 if df['quality'] <= 5. Instead, if this boolean value is true, then it keeps the original value in the dataset. After cleaning the data, I then trained the support vector classifier model using the fit method.
import numpy as np
from sklearn import preprocessing, model_selection, neighbors, svm
from sklearn.linear_model import LinearRegression
import pandas as pd
df = pd.read_csv('winequality-red.csv')
df['quality'].where(df['quality'] <= 5, 1, inplace=True)
df['quality'].where(df['quality'] > 5, 0, inplace=True)
X = np.array(df.drop(['quality'], 1))
y = np.array(df['quality'])
X_train, X_test, y_train, y_test = model_selection.train_test_split(
X, y, test_size=0.2)
clf = svm.SVC()
clf.fit(X_train, y_train)
In [119]: confidence = clf.score(X_test, y_test) print(confidence) 0.5875 In [120]: example = np.array([[4, 0.5, 1, 1, 1, 2, 2, 0.5, 0.3, 9, 1]]) example = example.reshape(len(example), -1) prediction = clf.predict(example) print(prediction) [1]
The accuracy score turned out to be quite low, and I didn't know why until I went back to the dataset and looked at it more closely. Turns out, features of a bottle of wine such as acidity, density, and sugar level all had their different proportionality to whether the wine has a high-quality score or not. For instance, low acidity makes a bottle of wine good whereas a high sugar level can also be an indicator of good quality wine. So, the values of some of the features may be directly proportional, inversely proportional, or even neither to the quality rating of a bottle of wine. Therefore, a simple support vector classifier with a linear hyperplane separating the data may not achieve the greatest results. And this is where kernel functions and nonlinear support vector machines come in.
To demonstrate the implementation of SVM, I found another dataset that contains about 10 years of daily weather observations from many locations across Australia, with the target variable being whether the day after the observation rains or not. Very interesting.

This data is quite big, consisting of 17 columns and a whopping 73411 days of records. As usual, I cleaned up the data a little bit by dropping a few columns (a lot of the columns contained strings and I couldn't be bothered to accommodate them in this SVM demonstration) and getting rid of the "NaN" values. The first column consisted of dates of the observations, which took the form of "2010-08-01". This would be hard to fit in the model so I stripped the string into just "8", or the month, for simplicity. I set the output "Y" as the "RainTomorrow" column, just like the quality column in the wine classification example above.
import numpy as np
from sklearn import preprocessing, model_selection, neighbors, svm
from sklearn.linear_model import LinearRegression
import pandas as pd
df = pd.read_csv('weatherAUS.csv')
df['Date'] = df['Date'].map(lambda x: str(x)[5:-3])
df = df.drop(['Location', 'Sunshine', 'Evaporation', 'WindDir9am', 'WindDir3pm', 'WindGustDir' ], 1)
df = df.dropna(inplace=True)
X = np.array(df.drop(['RainTomorrow', 'RainToday'], 1))
y = np.array(df['RainTomorrow'])
X_train, X_test, y_train, y_test = model_selection.train_test_split(
X, y, test_size=0.2)
clf = svm.SVC()
clf.fit(X_train, y_train)
In [119]:
confidence = clf.score(X_test, y_test)
print(confidence)
.8383845263229586
In [120]:
example = np.array([[4, 6.7, 30.7, 5.5, 60, 12, 9, 63, 999, 1011, 8, 2, 16.7, 28,8]])
example = example.reshape(len(example), -1)
prediction = clf.predict(example)
print("Is tomorrow going to rain", prediction)
Is tomorrow going to rain ['Yes']
Training this model took about 2 minutes which was quite long. But the result was quite nice!
SVM becomes not as accurate and powerful when it encounters outliers. This is when SVM with soft margins comes in handy! Soft margin SVM can be controlled and modulated by the C parameter. By tuning the C value, you can omit some outliers and therefore make your model more accurate!
for C in [ 10**x for x in range(10) ]:
clf = svm.SVC(C=C)
clf.fit(X_train, y_train)
confidence = clf.score(X_test, y_test)
print(confidence)
In scikit-learn, the c parameter in the SVM method can help tune that soft-hard margin and optimize the training model. In the above code, as suggested by this StackOverflow post, I looped over powers of 10 and tested the accuracy results. I also cut the dataset df = df.iloc[:3000], so that it runs faster.

The accuracy results converge at about $10^4$ to $10^5$. So that is where I guess the model is optimized, considering both efficiency and accuracy. For your reference, the image below shows what C parameter does and the idea of soft-hard margin




Nicely explained
so slay!